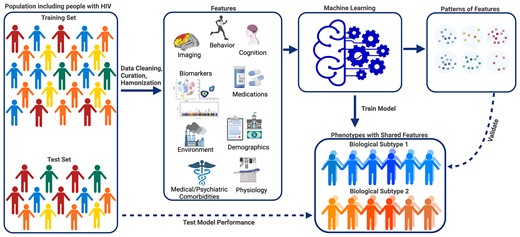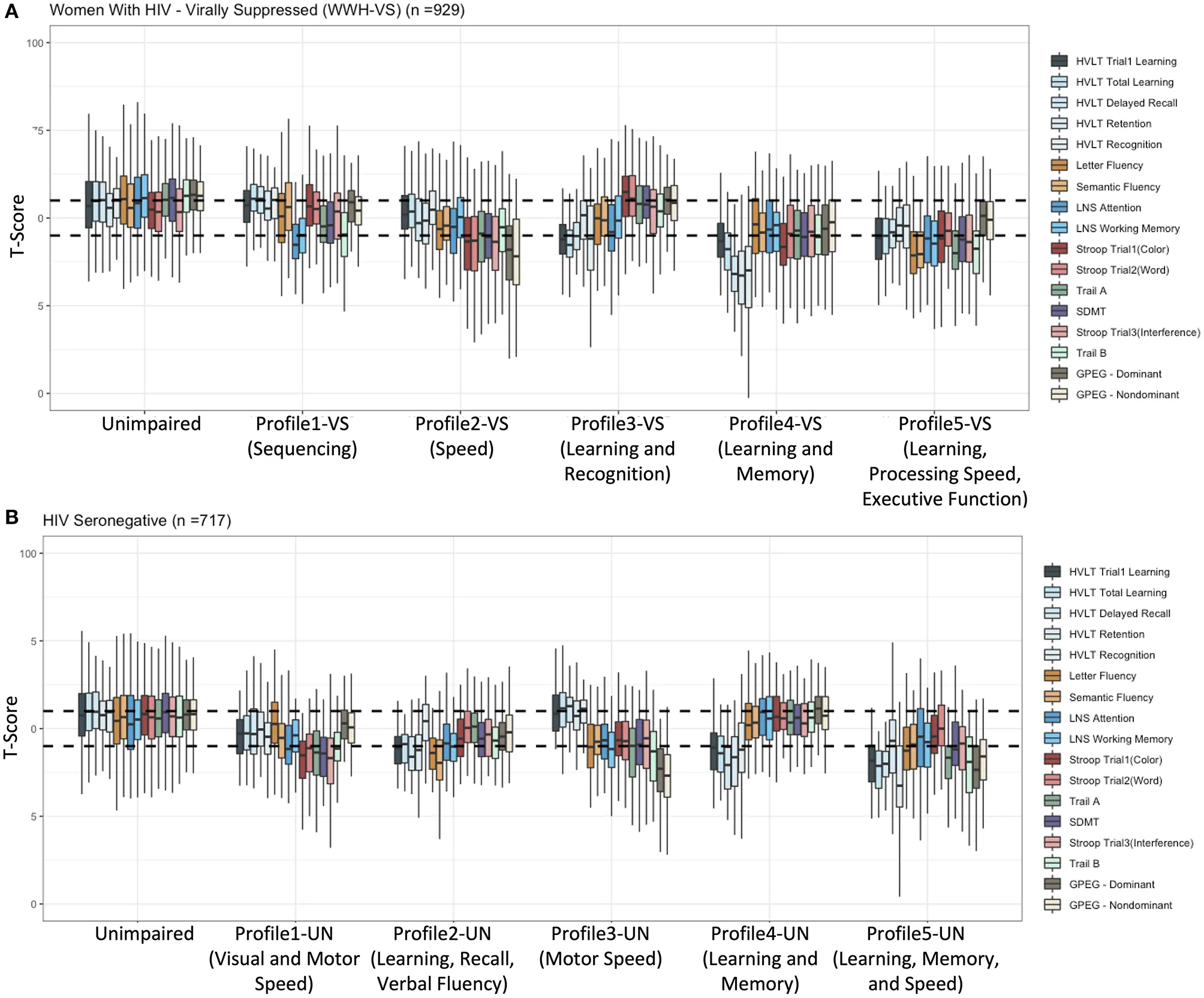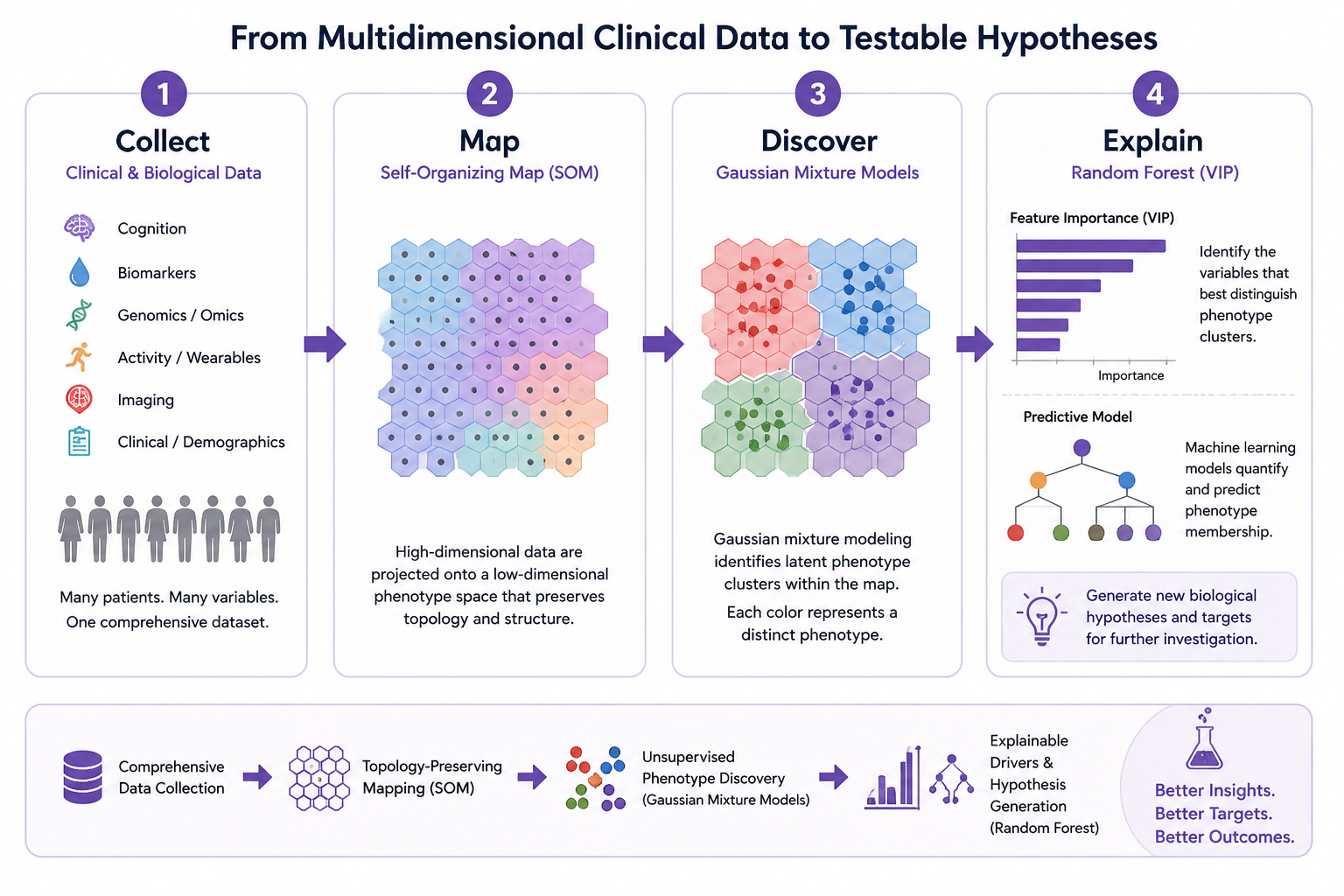
These pipelines are the computational layer for discovering hidden structure in heterogeneous translational data.
They are designed around reproducibility, model interpretation, and the ability to connect statistical structure to meaningful scientific and clinical questions.
Scientific Infrastructure
The pipelines combine dimensionality reduction, self-organizing maps, clustering, supervised modeling, variable importance, and visual interpretation. They are built to support both discovery and explanation: finding structure first, then asking what variables define or modify that structure.
Scientific Story
This thread began in NeuroHIV cognitive phenotyping and now supports broader translational questions in aging, Long COVID, mental health, sleep, and biomarker integration.